

Cuando visitamos diferentes webs, todas comparten aspectos en común. Todos los sitios se basan en una estructura donde el contenido de sus páginas y artículos está organizado en lo que conocemos como el mapa del sitio.
Esto es importante porque es uno de los aspectos para que nuestro sitio web sea tomado en cuenta por los motores de búsqueda. Además, hay un archivo cuya simple existencia puede facilitar el proceso de rastreo y acceso a nuestra web: el archivo robots.txt.

Este artículo está dedicado al archivo robots.txt para entender cómo funciona y cómo podemos darle una sintaxis acorde a nuestras necesidades.
Tabla de contenidos
¿Qué es el archivo robots.txt?
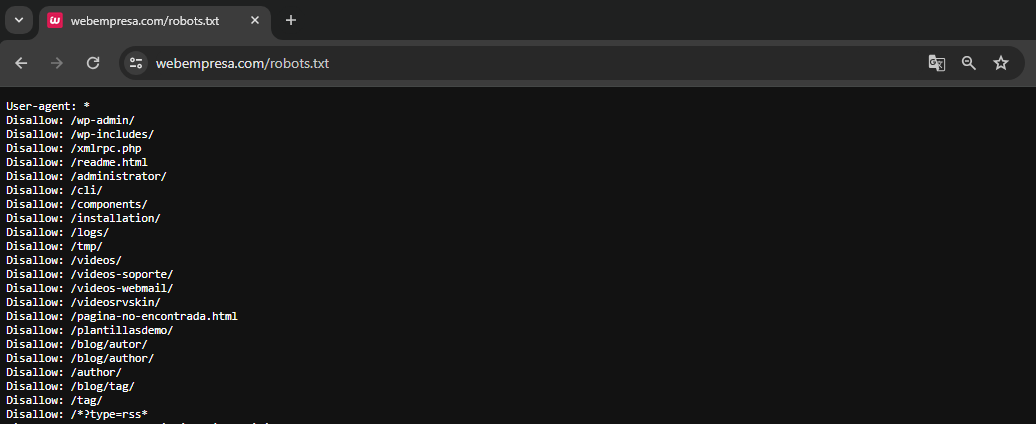
El archivo robots.txt es un archivo de texto simple que, por lo general, se encuentra ubicado en el directorio raíz de un sitio web para dar instrucciones a los motores de búsqueda sobre cómo deben interactuar con dicho sitio.
Este archivo forma parte del protocolo de exclusión de robots (REP, por sus siglas en inglés) Este protocolo es un estándar utilizado por los sitios web para establecer comunicación con los rastreadores web y motores de búsqueda sobre cuáles áreas de un sitio web deben y no deben ser rastreadas o indexadas.
El archivo robots.txt es el principal componente del REP, ya que nos proporciona la autoridad como propietarios del sitio web el poder controlar qué partes del sitio pueden ser rastreadas o indexadas por los bots de los motores de búsqueda y otros agentes web.
¿Cuál es la importancia del archivo robots.txt?
El uso del archivo robots.txt resulta ser fundamental en la gestión y el posicionamiento de un sitio web por varios motivos:
Control del rastreo de los bots: el archivo robots.txt nos permite como administradores del sitio web el poder especificar qué partes del sitio deben o no deben ser rastreadas por los motores de búsqueda.
Evitar la sobrecarga del servidor: considerando el poder que tenemos ya definido en el punto anterior, una de las capacidades es el poder bloquear áreas innecesarias del sitio, se reduce la carga en el servidor y se asegura que los recursos se concentren en las páginas que consideremos más importantes.
Proteger áreas sensibles: no solo podemos bloquear páginas concretas, también es posible excluir directorios como /admin/, /private/, o cualquier área que no esté destinada al público o que contenga información confidencial.
Ocultar contenido en concreto: el ocultar o excluir recursos como PDF, vídeos e imágenes utilizando el archivo robots.txt es una estrategia efectiva para gestionar cómo los motores de búsqueda interactúan con el contenido de un sitio web. Esto puede ser particularmente útil si queremos mantener ciertos recursos en privado o bien se desea que los motores de búsqueda se centren en otros contenidos más importantes del sitio.
Mejora de la eficiencia de indexación: al realizar una configuración de directivas específicas, los motores de búsqueda pueden centrarse en indexar el contenido que consideremos más relevante y valioso del sitio web. Esto se traduce en una mejora en la eficiencia del rastreo y puede resultar en una mejor clasificación de las páginas más importantes.
Optimización del presupuesto de rastreo: cada sitio web tiene un “presupuesto de rastreo” asignado por los motores de búsqueda, este presupuesto se trata de la cantidad de páginas que el bot rastrea en un período de tiempo determinado. Al dirigir a los bots a las páginas con mayor importancia, además de evitar que rastreen contenido duplicado o de baja prioridad, se maximiza el uso de este presupuesto o recurso.
Prevención de la indexación de contenido duplicado: al tener la libertad de poder bloquear ciertos apartados del sitio, como versiones de desarrollo o archivos temporales, se puede evitar que el contenido duplicado sea indexado, lo cual puede afectar de forma negativa el posicionamiento del sitio web.
Mejor experiencia de usuario: bloquear los bots de ambientes de prueba o de desarrollo puede prevenir que los usuarios lleguen a páginas incompletas o en construcción a través de resultados de búsqueda, evitando que sean consideradas por los motores de búsqueda y así mejorando así la experiencia general del usuario.
¿Cómo funciona el archivo robot.txt?
Como sabemos, el archivo robots.txt contiene directivas que guían a los motores de búsqueda cuando rastrean un sitio web. Estas directivas ayudan a los motores de búsqueda a encontrar, evaluar e indexar el contenido.
El contenido que pase por este proceso se incluirá progresivamente en los resultados de búsqueda, lo que es una de las principales metas en cuanto a posicionamiento web se refiere.
Los “bots” enviados por los motores de búsqueda son los responsables de esta tarea. Cuando un motor de búsqueda evalúa un sitio web, lo primero que los bots buscan es el archivo robots.txt.
La interpretación del contenido del archivo robots.txt por parte de los bots es sencilla, ya que este archivo consta de directivas que los bots saben interpretar.
Por otro lado, la sintaxis del archivo se resume en una serie de reglas que, en teoría, deben ser cumplidas. Sin embargo, es importante tener en cuenta que, así como existen bots que ayudan a los motores de búsqueda a indexar nuestro contenido valioso, también hay “bots maliciosos” que buscan vulnerabilidades y generan spam en nuestro sitio web.
Estos últimos pueden ignorar las reglas y directivas establecidas en el archivo robots.txt.
¿Dónde está el archivo robots.txt?
Al momento de definir al archivo robots.txt hemos dicho que “por lo general se encuentra ubicado en el directorio raíz de un sitio web”, este es el deber ser, el archivo debe estar alojado en nuestro servidor, en el directorio que contiene la instalación de nuestro sitio web.
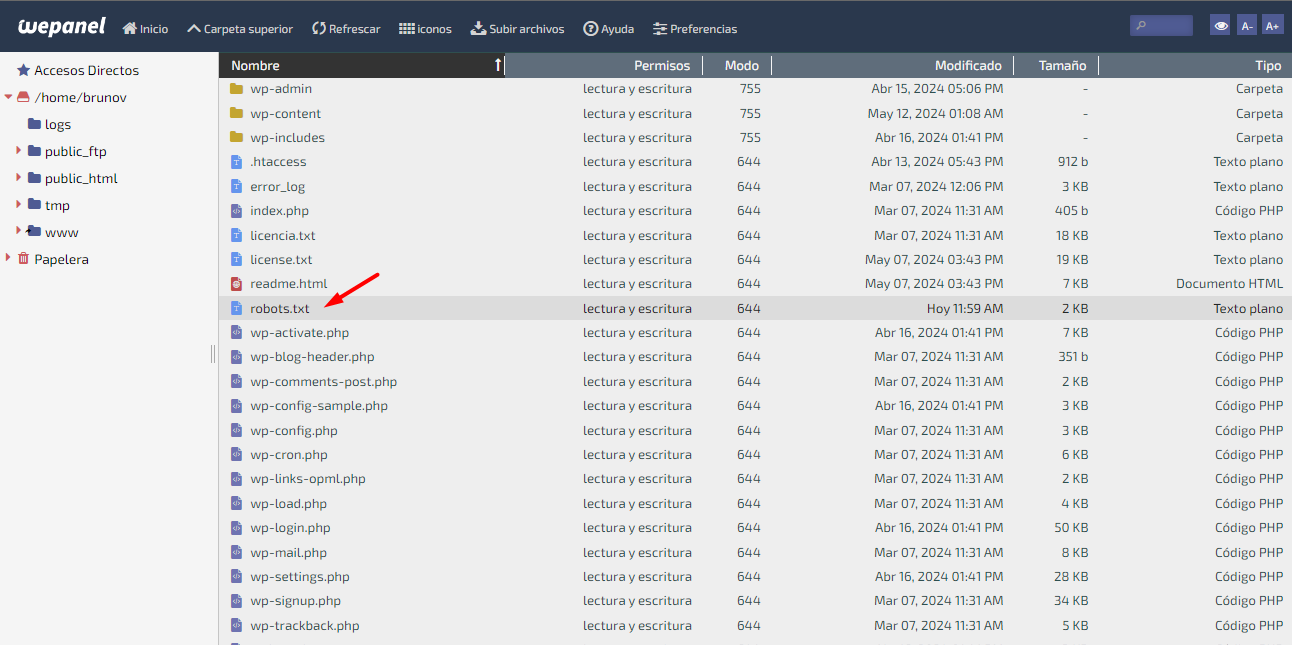
Sin embargo, esto puede variar según la plataforma en línea o el CMS utilizado, ya que los métodos para crear, encontrar y editar el archivo robots.txt pueden diferir. Abordaremos estas variaciones más adelante en el artículo.
Por último, pero no menos importante, dado que el archivo robots.txt debe estar siempre en la raíz del sitio web, siempre podemos consultar el archivo de cualquier página que visitemos agregando “/robots.txt” a la URL. Por ejemplo, “https://www.webempresa.com/robots.txt”.
Sintaxis del archivo robots
El archivo robots.txt está compuesto por varias directivas o reglas, las cuales se encargan de controlar cómo los motores de búsqueda deben interactuar con nuestro sitio web.
La sintaxis de estas directivas por lo general están conformadas por un “user-agent” el cual determina el bot que corresponde a un motor de búsqueda y una instrucción que define si el elemento, archivo, página o URL será aprobada o bloqueada por medio de “allow” y “disallow”.
Para comprenderlo mejor vamos a explicar cada comando y para qué funciona a continuación.
User-agent
La directiva User-agent especifica a qué bots se aplican las reglas que van a cumplir en la siguiente línea.
User-agent: Googlebot
Cada motor de búsqueda tiene su propio nombre de bot.
User-agent: *
También se suele usar el símbolo de “*” para casos en los que, en lugar de introducir el nombre de un bot en concreto, queremos que la instrucción se aplique a todos los bots existentes.
Disallow
La directiva Disallow indica a los bots qué directorios o páginas no deben ser rastreados.
Disallow: [ruta del directorio o página]
Si se deja vacío, el comando de Disallow:, significa que no hay restricciones para los bots.
Por ejemplo, en este caso queremos bloquear el acceso al directorio /prueba/
Disallow: /prueba/
O en este otro caso queremos bloquear el directorio /text.html
Disallow: /test.html
Allow
La directiva Allow es la contraparte de la directiva Disallow, esta nos permite el rastreo de subdirectorios o páginas específicas dentro de un directorio que está bloqueado por una directiva Disallow.
Allow: [ruta del directorio o página]
La autoridad del comando Allow se puede ejemplificar de la siguiente manera, en la siguiente directiva estamos permitiendo el acceso a /prueba/index.html incluso si el directorio /prueba/ pueda encontrarse bloqueado por Disallow.
Allow: /prueba/index.html
Es necesario destacar que al momento de colocar rutas de los elementos a permitir o bloquear por medio de las directivas ya explicadas es que son sensibles a las mayúsculas, lo que quiere decir que /Pruebas/ no es la misma ruta que /pruebas/.
Sitemap
La directiva Sitemap invoca de forma directa la ubicación del mapa del sitio de la página a la que pertenece el archivo robots.txt, esta es una ayuda a los motores de búsqueda a encontrar y rastrear todas las páginas listadas en el sitemap.
Sitemap: https://www.tusitio.com/sitemap.xml
Con esta directiva le decimos a los bots dónde pueden encontrar el sitemap del sitio.
Crawl-delay
La directiva Crawl-delay indica a los bots cuánto tiempo deben esperar entre solicitudes que realizan de manera sucesiva al servidor. Cabe destacar que no todos los bots respetan esta directiva y su implementación puede variar según el bot y su respectivo motor de busqueda.
Crawl-delay: [número de segundos]
Al establecer la directiva le decimos al bot que espere 10 segundos entre solicitudes, el número puede variar, pero siempre está represando en segundos.
Crawl-delay: 10
Noindex
La directiva Noindex se utiliza para indicar a los bots que no indexen una página en concreto. Es importante destacar que esta directiva ya no es parte del estándar robots.txt y no todos los motores de búsqueda la soportan o la tienen en cuenta.
Noindex: [ruta del directorio o página]
El uso habitual de esta directiva era de la siguiente manera, haciendo la sugerencia a los bots que no indexar la página /pruebas.html
Noindex: /pruebas.html
Comentarios (#)
En el archivo robots.txt no solo podemos agregar comandos y directivas, también es posible dejar comentarios. Los comentarios se utilizan para agregar anotaciones o descripciones que pueden ayudar a los administradores a entender las reglas definidas.
# Bloquear el directorio de pruebas Disallow: /pruebas/
Buenas prácticas
Con la información que ya conocemos estamos más que listos para poder armar por nosotros mismos nuestro archivo de robots.txt sin embargo antes de comenzar hay algunas consideraciones que vale la pena tener en cuenta mientras le damos forma al contenido del archivo.
Colocar nuevas líneas para cada comando: debemos procurar que al momento de agregar una directiva (User-agent, Disallow, Allow, etc.) esta se encuentre en una nueva línea para mejorar la legibilidad y evitar confusiones.
Usar cada user-agent una vez: si bien podemos invocar los “user-agent” que queramos, lo ideal es que usemos las reglas para cada bot solo una vez. Si se requieren diferentes reglas para diferentes bots, podemos agruparlas claramente bajo su propio user-agent.
Emplear los comodines para aclarar las indicaciones: el uso de los comodines (*) es realmente util cuando queremos aplicar reglas a múltiples archivos o directorios. Por ejemplo, establecer (*) puede representar cualquier secuencia de caracteres, cualquier bot o cualquier subdirectorio según el caso que se use.
Por ejemplo, en la siguiente regla estamos bloqueando todas las URL que contengan “paginaprueba” sin importar su posicion.
Disallow: /*/ paginaprueba/
Usar el símbolo “$” para indicar el final de una URL: otro caracter que es de extrema utilidad es el símbolo de ($) el cual se utiliza para indicar que la regla debe aplicarse solo al final de la URL. Esto es útil para evitar conflictos con rutas que sean similares.
Por ejemplo, si deseamos bloquear todas las URL que finalicen con el término “paginaprueba” debemos finalizar la ruta con ($).
Disallow: /* paginaprueba$
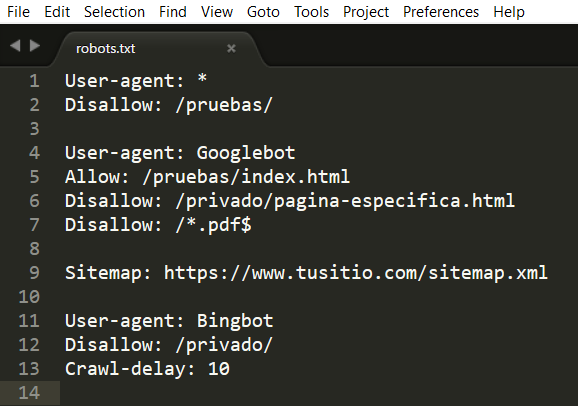
Para terminar la estructura de nuestro archivo robots.txt sería algo similar al siguiente, ya tenemos la capacidad de leerlo y entenderlo sin mayor complicación.
User-agent: * Disallow: /pruebas/ User-agent: Googlebot Allow: /pruebas/index.html Disallow: /privado/pagina-especifica.html Disallow: /*.pdf$ Sitemap: https://www.tusitio.com/sitemap.xml User-agent: Bingbot Disallow: /privado/ Crawl-delay: 10
Utiliza archivos robots.txt distintos para diferentes subdominios: Un punto interesante que no sabemos dejar pasar desapercibido es el uso que le damos al archivo robot.txt. Cada subdominio debe tener su propio archivo robots.txt. Por ejemplo, blog.tusitio.com/robots.txt debe ser independiente de www.tusitio.com/robots.txt.
# Para blog.tusitio.com User-agent: * Disallow: /
¿Cómo crear un archivo robots.txt?
Crear un archivo robots.txt es un proceso sencillo, pero requiere atención a ciertos detalles para asegurar que funcione correctamente y cumpla con las necesidades que tenemos en base a nuestro sitio web.
Crear el archivo robots.txt desde un editor de texto
Podemos comenzar por abrir nuestro editor de texto de preferencia (puede ser Notepad, Sublime Text, VSCode, etc.).
Con el editor ya abierto vamos a crear un nuevo archivo para luego guardarlo con el nombre robots.txt.
Aquí ya podemos añadir todas las directivas que consideramos necesita nuestro sitio web. Debemos tener presente las buenas prácticas que ya hemos explicado como que cada directiva esté en una nueva línea y que cada user-agent tenga su propio bloque de directivas.
Al terminar de editar el archivo vamos a guarda los cambios en el archivo ya creado, puede ser redundante, pero validemos siempre que el archivo esté guardado con el nombre de “robots” y con la extensión “.txt”.
Sube el archivo robots.txt al sitio web
Una vez que hemos creado nuestro archivo robots.txt en local, solo queda subirlo al directorio raíz de nuestro sitio web. Recordemos que el directorio raíz es la carpeta principal que alberga otros archivos como index.html o index.php.
Este proceso puede variar según la plataforma o CMS que estemos utilizando, ya que cada uno puede manejar el archivo robots.txt de manera diferente. Sin embargo, presentaremos la opción más convencional y general para cualquier caso.
Si tenemos acceso a nuestro hosting web, es probable que contemos con una interfaz para gestionar los archivos alojados, como un administrador de archivos.
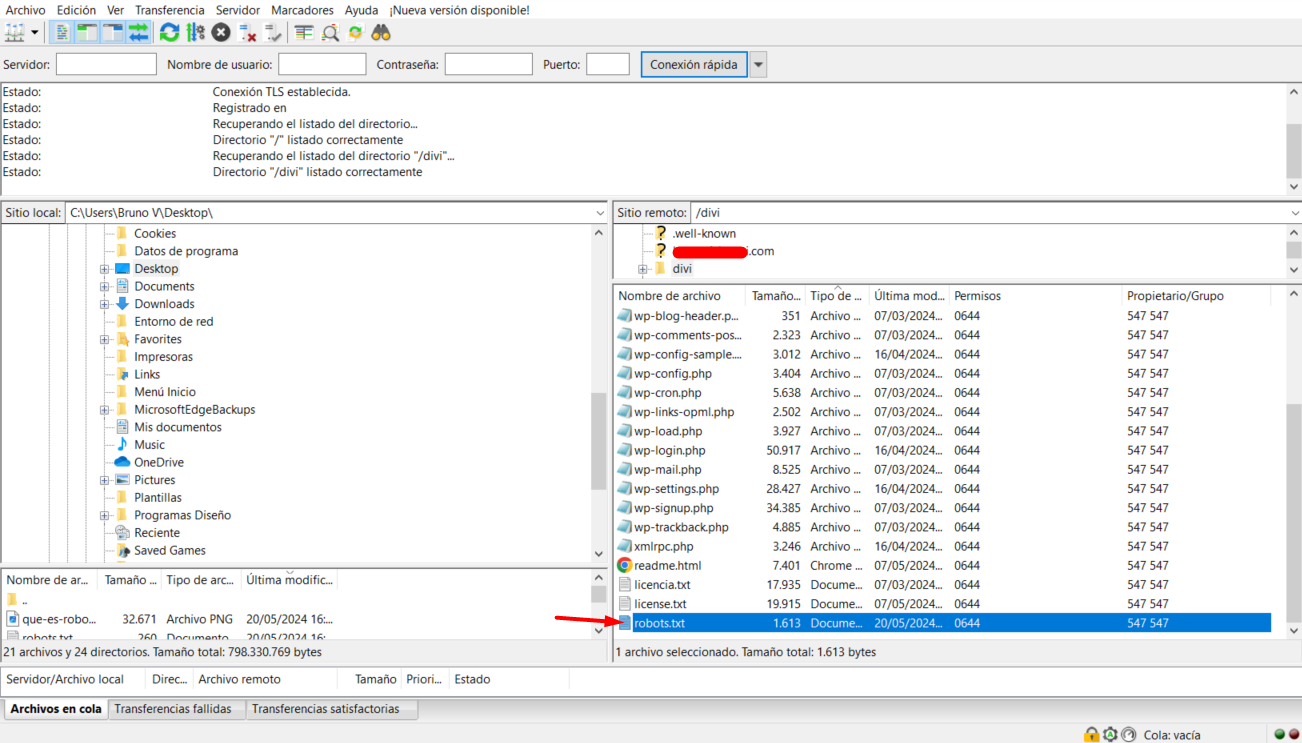
Otra opción válida es cargar el archivo mediante un cliente FTP, utilizando un programa popular como FileZilla.
Para los casos más concretos en otras plataformas populares y CMS recomendamos échale un vistazo a los siguientes enlaces de interés.
- Gestionar archivo robot.txt en Wix
- Gestionar archivo robot.txt en Joomla
- Gestionar archivo robot.txt en Shopify
- Gestionar archivo robot.txt en BigCommerce
Verifica el archivo robots.txt
Hemos llegado a uno de los pasos más esperados: validar que el archivo robots.txt funcione correctamente y pueda ser visualizado. Existen varias formas de verificar esto, siendo la más simple irónicamente la que mencionamos al inicio de este artículo.
Cualquier sitio web con su archivo robots.txt correctamente configurado debe ser accesible visitando https://www.elsitioweb.com/robots.txt desde nuestro navegador.
Otra opción es consultar directamente desde la herramienta disponible en Google Search Console al asociar nuestro sitio web.
Esta herramienta, conocida como “Informe de robots.txt”, analiza el archivo robots.txt que hemos cargado en nuestro sitio web y genera una serie de métricas y validaciones que nos ayudarán a comprobar su estado y correcto funcionamiento.

(Visita el sitio web haciendo clic en la imagen ↑)
Conclusión
En nuestro recorrido, hemos visto que el uso del archivo robots.txt es de vital importancia para cualquier sitio web que pretenda destacarse en el vasto océano de internet.
Este simple, pero potente archivo de texto, desempeña un papel crucial en la interacción entre nuestro sitio web y los motores de búsqueda, permitiendo controlar qué apartados, páginas, archivos y URLs pueden ser rastreados e indexados. Al especificar estas directivas, podemos evitar que se indexen páginas duplicadas, secciones en desarrollo o áreas privadas, mejorando así la experiencia del usuario y optimizando el rendimiento general del sitio al liberar recursos del servidor.
Además, el archivo robots.txt contribuye significativamente a la optimización para motores de búsqueda (SEO). Al guiar a los motores de búsqueda hacia el contenido que consideramos más relevante, aumentamos las probabilidades de que el sitio aparezca en las primeras posiciones de los resultados de búsqueda, lo que se traduce en mayor tráfico, visibilidad y éxito en línea. De este modo, el archivo robots.txt se convierte en una herramienta esencial para mejorar el posicionamiento de cualquier sitio web.
Finalmente, aunque el archivo robots.txt no garantiza la seguridad absoluta de un sitio web, juega un papel importante en la protección de información sensible al limitar o bloquear a los bots de rastrear ciertos contenidos. Esta práctica, combinada con herramientas de análisis como Google Search Console, nos permite monitorear y ajustar continuamente la configuración del archivo para asegurar su correcto funcionamiento.
Sin duda, el archivo robots.txt es un pequeño gigante que no debe ser ignorado, ya que su uso maximiza la eficiencia, seguridad y visibilidad de cualquier sitio web, convirtiéndose en una práctica estándar esencial para cualquier persona que quiera posicionar su sitio web.
También te puede interesar:
- Disuadir a los motores de búsqueda de indexar este sitio
- Cómo indexar una página WordPress en Google
- No Index WordPress, Qué significa y cómo configurarlo
- Administrador de archivos WordPress sencillo
- ¿Cómo crear un sitemap para Google News en WordPress?
- Instalar y configurar Google Tag Manager en WordPress
¿Te ha resultado útil este artículo?

Equipo de soporte WordPress y Woocommerce en Webempresa.








