

Cuando visitamos una página web y podemos leer y comprender su contenido, o incluso cuando recibimos un correo electrónico, todos los caracteres que forman las palabras, sin importar su idioma, están respaldados por un sistema de codificación.
En idiomas como el español o el francés, que incluyen caracteres especiales como acentos o la letra “ñ”, existe un estándar de codificación que, tras bastidores, garantiza que todas las letras, números e incluso emojis se muestren correctamente en los sitios web.

Estos caracteres se pueden visualizar y, si es necesario, traducir según nuestras necesidades. Por ejemplo, este artículo está escrito en español, pero cualquier visitante de otro idioma, aunque no lo entienda, podrá verlo sin inconvenientes.
A continuación, veremos el sistema de codificación de caracteres Unicode UTF-8 y su importancia como estándar en las aplicaciones web en Internet.
Tabla de contenidos
¿Qué es Unicode?
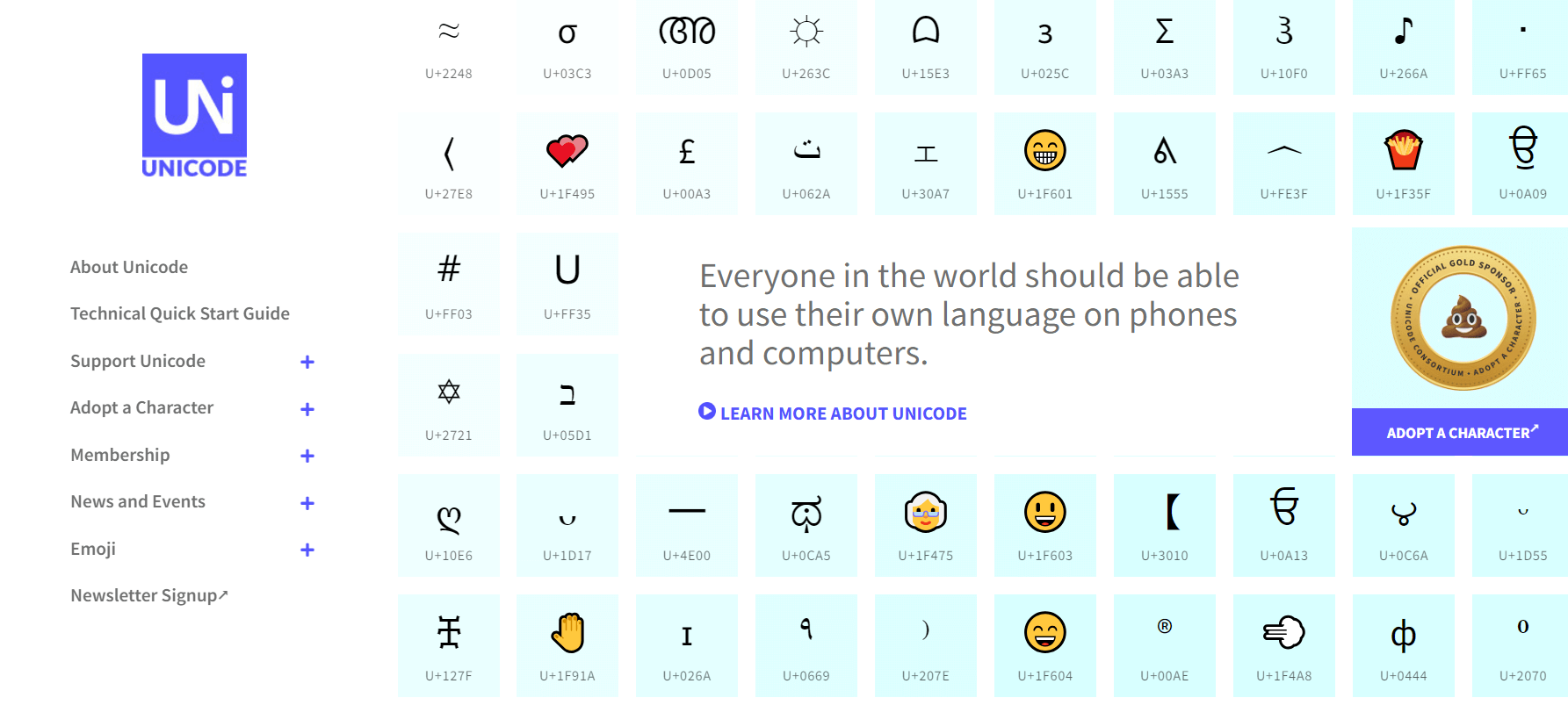
(Visita el sitio web haciendo clic en la imagen ↑)
Antes de definir y profundizar en lo que se refiere a UTF-8 es importante que podamos comprender de qué se trata “Unicode”.
Unicode es un estándar de codificación de caracteres diseñado para representar de manera consistente y universal en forma de texto cualquier sistema de escritura utilizado en el mundo.
El objetivo principal de este estándar es permitir la interoperabilidad entre diferentes sistemas informáticos y aplicaciones, asegurando que los textos sean interpretados de forma correcta, sin importar el idioma o el entorno.
Entre las características interesantes que podemos destacar del estándar de codificación Unicode podemos mencionar los siguientes:
Entendimiento para todos: Unicode, como hemos mencionado, se encarga de incluir caracteres de casi todos los idiomas y sistemas de escritura, así como símbolos técnicos, matemáticos, emojis y otros signos.
Codificación: cada carácter en Unicode posee una sintaxis por la cual puede ser invocado, la estructura de este formato se presenta de la siguiente manera.
Cada carácter posee un número único llamado punto de código (code point), que se representa en el formato U+XXXX. Por ejemplo:
La letra “A” mayúscula tiene el punto de código U+0041.
El emoji 😃 tiene el punto de código U+1F603.
Estos códigos no debemos aprenderlos de memoria, sin embargo, si queremos sacarle el máximo provecho, existen sitios web donde podemos buscar símbolos y emojis para copiarlos y pegarlos en nuestros mensajes, asuntos, contenidos o cualquier otro uso.

(Visita el sitio web haciendo clic en la imagen ↑)
Compatibilidad con otros estándares de codificación: los primeros 128 caracteres de Unicode coinciden con el conjunto de caracteres ASCII, haciendo mucho más sencilla la transición y compatibilidad con sistemas más antiguos.
Por otro lado, Unicode se encarga de resolver los problemas de compatibilidad que presentaban con los estándares anteriores, como ASCII o ANSI, que no podían representar muchos idiomas o símbolos.
Para tener más contexto, cuando hablamos de ASCII (American Standard Code for Information Interchange) nos referimos a un estándar de codificación de caracteres desarrollado en 1963 creado para representar texto en sistemas informáticos y dispositivos de comunicación.
ANSI (American National Standards Institute) por su parte, se trata de un término más genérico y menos definido cuando se refiere a codificación de caracteres, ya que no es un estándar específico de codificación como ASCII.
A menudo se usa para referirse a las codificaciones de caracteres extendidas basadas en ASCII y utilizadas en sistemas operativos como Windows.
De esta manera, podemos disfrutar del internet tal como lo conocemos hoy gracias a Unicode, una herramienta esencial para la globalización de las tecnologías. Este estándar permite que los sistemas informáticos gestionen texto de manera confiable en un entorno multilingüe.
Tipos de codificaciones UTF
Unicode puede representarse en diferentes formas de codificación, que podemos encontrar bajo el nombre de UTF (Unicode Transformation Format).
Básicamente, se trata de las distintas formas en las cuales se pueden representar los puntos de código de Unicode en bytes para ser almacenados o transmitidos. Cada tipo de codificación tiene ventajas y desventajas dependiendo del contexto en el que se utilice.
A continuación vamos a definir las 3 formas en las que se pueden codificar los caracteres de Unicode.
UTF-8
UTF-8 se trata de una codificación de longitud variable, la cual utiliza entre 1 y 4 bytes para representar caracteres Unicode.
Resulta ser la codificación más utilizada en sistemas modernos debido a su alta compatibilidad con ASCII y su eficiencia en textos basados en lenguajes occidentales.
Características destacadas:
- Longitud variable: los caracteres más simples (ASCII) usan 1 byte, mientras que los caracteres menos comunes usan entre 2, 3 o 4 bytes.
- Compatibilidad con ASCII: como ya hemos mencionado, los primeros 128 caracteres Unicode coinciden exactamente con los caracteres ASCII, por lo que es retrocompatible con sistemas más antiguos.
- Sin ambigüedad: los patrones de bits aseguran que no se generen conflictos entre los diferentes tamaños de caracteres, lo que facilita la detección y corrección de errores.
Ventajas:
- Eficiencia en almacenamiento: UTF-8 es ideal para textos predominantemente en inglés u otros idiomas basados en ASCII.
- Soporte universal: es por defecto la codificación predeterminada en los sitios web, sistemas de archivos modernos y bases de datos.
- Compatibilidad con tecnologías modernas: UTF-8 se comporta bien con programas de software y protocolos diseñados para redes y almacenamiento.
Desventajas:
- Mayor complejidad en procesamiento: los caracteres dispuestos en UTF-8 pueden tener diferentes longitudes, lo que dificulta operaciones como indexado directo.
- Menos eficiente en idiomas con caracteres complejos: podemos encontrarnos en la situación en la cual idiomas con caracteres en chino o árabe, los caracteres van a requerir de 3 o más bytes.
UTF-16
UTF-16 se trata de otra forma de codificación de longitud variable, la cual utiliza 2 bytes (16 bits) para representar caracteres del Plano Multilingüe Básico (BMP) y 4 bytes para los caracteres fuera de este rango.
UTF-16 resulta muy popular en ciertos entornos y sistemas operativos como Windows y plataformas como Java.
Características destacadas:
- Longitud variable: en UTF-16 la mayoría de los caracteres comunes usan 2 bytes. Por otro lado, los caracteres fuera del BMP (como emojis o caracteres históricos) requieren un par sustituto, lo que ocupa 4 bytes.
- Comprime caracteres del BMP: UTF-16 puede compactar los caracteres del BMP incluyendo muchos alfabetos modernos como latín, cirílico, griego y los caracteres más usados del chino y japonés.
- No compatible con ASCII: UTF-16 para poder ser compatible con caracteres ASCII requiere decodificación previa para poder interoperar con este tipo de sistema.
Ventajas:
- Eficiencia en ciertos idiomas: UTF-16 resulta ideal para textos en chino, japonés, coreano u otros lenguajes que tienen una alta densidad de caracteres del BMP.
- Uso en plataformas populares: este tipo de codificación suele ser el estándar interno para muchos entornos de programación, como .NET y Java.
- Fácil conversión al BMP: UTF-16 al ser eficiente en este rango de bits, es comúnmente usado en sistemas orientados a este grupo de caracteres.
Desventajas:
- Mayor tamaño para textos ASCII: en UTF-16 cada carácter ocupa un mínimo de 2 bytes, lo que lo hace menos eficiente para idiomas occidentales.
- Mayor complejidad para caracteres fuera del BMP: para UTF-16 el manejar los pares sustitutos requiere más trabajo en su procesamiento.
UTF-32
UTF-32 es la 3.ª forma de codificación de longitud fija donde cada carácter Unicode se representa con exactamente 4 bytes (32 bits).
Es extremadamente simple, ya que el punto de código Unicode coincide directamente con el valor binario almacenado (cada carácter por 4 bytes).
Características destacadas:
- Longitud fija: en UTF-32 cada carácter ocupa exactamente 4 bytes, independientemente de su punto de código.
- Simetría: UTF-32 no necesita cálculos para determinar la posición o el tamaño de un carácter.
- Codificación no optimizada: UTF-32 consume mucho espacio en comparación con sus contrapartes UTF-8 y UTF-16.
Ventajas:
- Fácil procesamiento: UTF-32 al contar con una longitud fija, las operaciones como indexado y búsqueda son directas.
- Sin necesidad de pares sustitutos: todo el rango de Unicode en UTF-32 se representa directamente sin requerir transformaciones adicionales.
- Ideal para procesamiento interno: el uso de UTF-32 resulta adecuado en sistemas donde la simplicidad y la consistencia son más importantes que el tamaño de almacenamiento.
Desventajas:
- Desperdicio de espacio: los textos basados en ASCII o BMP ocupan mucho más espacio usando UTF-32 en comparación con UTF-8 y UTF-16.
- Menor soporte en sistemas: UTF-32 No es tan ampliamente utilizado como las otras codificaciones, excepto en aplicaciones específicas las cuales le sacan el máximo provecho.
Comparativa entre codificaciones UTF
Ya a este punto de nuestro recorrido podemos diferenciar las distintas formas en las cuales se puede emplear el estándar de codificación Unicode; sin embargo, la elección de una codificación UTF depende de varias características que debemos tener presente.
Como por ejemplo, es indispensable mantener el equilibrio entre la eficiencia en espacio, el rendimiento y la simplicidad necesarios para el sistema o aplicación en cuestión.
UTF-8 es el estándar para la mayoría de los casos modernos, pero UTF-16 y UTF-32 tienen sus nichos específicos en aplicaciones técnicas.
Para presentarlo aún más claro dejaremos el siguiente listado con una comparativa simplificada.
UTF-8
Tamaño por carácter: 1-4 bytes.
Adecuado para: textos en inglés, web, sistemas ASCII.
Principal uso: sitios web, bases de datos, archivos de texto.
UTF-16
Tamaño por carácter: 2-4 bytes.
Adecuado para: textos en idiomas asiáticos o basados en el BMP.
Principal uso: aplicaciones empresariales, software de escritorio.
UTF-32
Tamaño por carácter: 4 bytes.
Adecuado para: procesamiento interno o acceso directo a caracteres.
Principal uso: sistemas internos, herramientas de análisis.
¿Cuál es la importancia de UTF-8 en la actualidad?
Regresando a darle protagonismo a UTF-8 hemos podido apreciar que se trata del estándar de codificación más importante en la actualidad debido a su amplia compatibilidad, eficiencia y soporte en sistemas globales.
Su implementación de manera masiva se debe a que es capaz de manejar texto en cualquier idioma, es retrocompatible con ASCII y es eficiente tanto en almacenamiento como en transmisión de datos.
Entre los aspectos clave que ya conocemos de UTF-8 hay apartado en los que su relevancia debe ser destacada, por ejemplo:
Globalización: por medio de UTF-8 es posible representar texto de prácticamente cualquier sistema de escritura, desde alfabetos como el latín y cirílico hasta idiomas asiáticos (chino, japonés, coreano) y escrituras más complejas como el árabe o devanagari.
La capacidad de UTF-8 para incluir símbolos técnicos, matemáticos y emojis lo hace ideal para aplicaciones modernas.
Compatibilidad con ASCII: un aspecto que puede parecer recurrente, pero es de extrema valía, es la retrocompatibilidad de UTF-8 con sistemas ASCII, lo que significa que cualquier texto ASCII válido también es texto UTF-8 válido. Esto facilita la transición de sistemas antiguos a Unicode.
Eficiencia en almacenamiento: UTF-8 solo usa un 1 byte para los caracteres ASCII, lo que lo hace muy eficiente para idiomas que utilizan estos caracteres de manera predominante, como el inglés, español, francés, alemán, entre otros.
Estandarización: UTF-8 se proclama como el formato estándar predeterminado en toda la web, según el Consorcio W3C. La mayoría de los navegadores web, sistemas operativos y herramientas de desarrollo asumen UTF-8 como su codificación principal.
Soporte generalizado: UTF-8 al ser ya un sistema de codificación estandarizado, resulta ampliamente compatible con sistemas operativos modernos, bases de datos, servidores web, APIs y lenguajes de programación. De esta manera es mucho más simple el desarrollo de aplicaciones multilingües.
Interoperabilidad: UTF-8 nos permite garantizar que los datos puedan ser compartidos entre diferentes sistemas y plataformas sin pérdida de información ni errores de interpretación de caracteres.
Casos de uso donde UTF-8 es indispensable
Ahora que comprendemos mejor la importancia de la codificación UTF-8, no hay mejor manera de apreciar su impacto que explorando casos de uso reales en los que está presente en nuestras tareas cotidianas.
Para ello, destacaremos varios ámbitos en los que la codificación UTF-8 desempeña un papel fundamental.
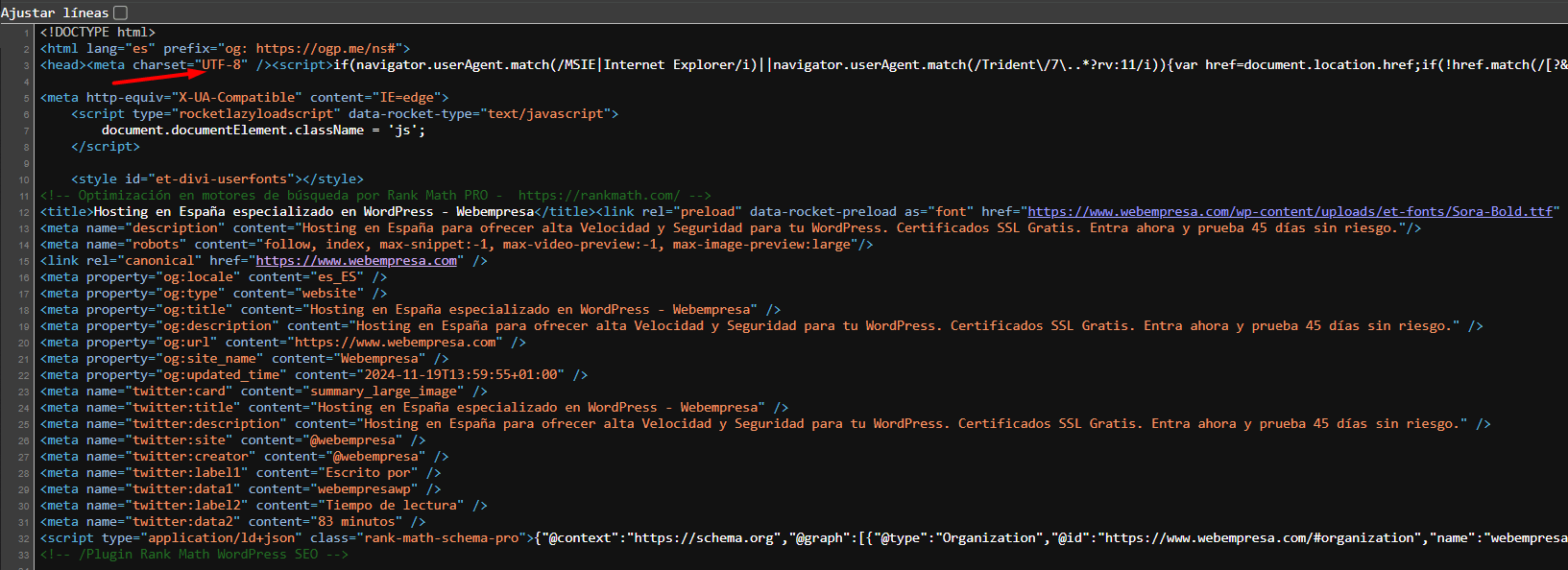
Desarrollo de sitios web: los navegadores modernos están capacitados para interpretar de manera automática el contenido en UTF-8, lo que garantiza la correcta visualización de páginas web multilingües.
Los archivos HTML, CSS y JavaScript suelen estar codificados en UTF-8 para evitar problemas con caracteres especiales o símbolos que no sean ASCII.
Bases de datos: en sistemas que almacenan datos multilingües (como una base de datos en WordPress), como nombres, direcciones y mensajes de usuarios, UTF-8 es ideal porque optimiza el espacio para caracteres comunes y permite almacenar idiomas diversos sin configuraciones adicionales.
(Visita el sitio web haciendo clic en la imagen ↑)
Sistemas de mensajería y redes sociales: aplicaciones de uso cotidiano como WhatsApp, Twitter(X) y Facebook utilizan UTF-8 para manejar mensajes de texto que pueden incluir cualquier idioma o emoji.
APIs y servicios web: la mayoría de las APIs modernas que podemos invocar (REST, GraphQL, SOAP) utilizan UTF-8 como estándar para enviar y recibir datos en JSON, XML o texto plano.
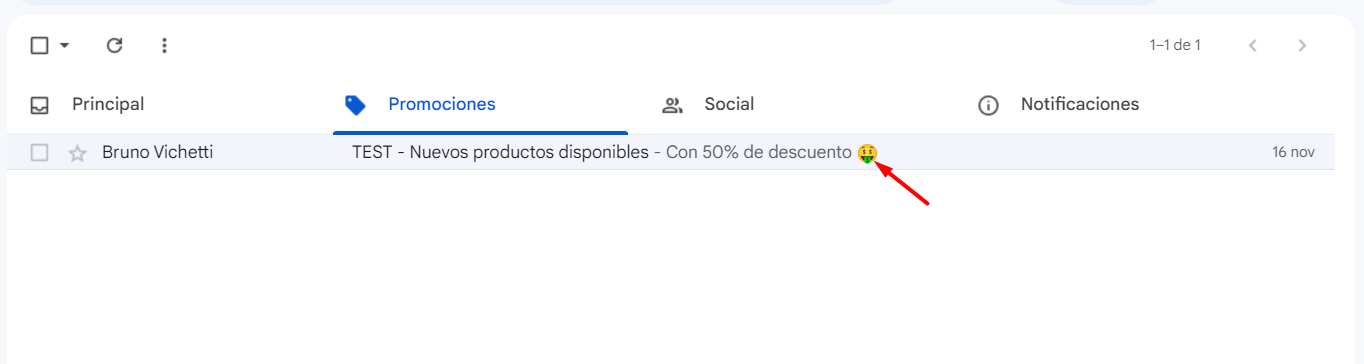
Correos electrónicos: el formato MIME (utilizado para correos electrónicos) admite UTF-8 para garantizar que los mensajes puedan incluir texto en diferentes idiomas y alfabetos, incluso emojis.
Archivos de configuración y scripts: muchos archivos de configuración de sistemas operativos y aplicaciones se encuentran codificados en UTF-8 para garantizar la portabilidad y la interpretación correcta de caracteres especiales.
Sistemas operativos y terminales: los sistemas basados en Unix/Linux y macOS utilizan UTF-8 como codificación predeterminada, asegurando que las aplicaciones puedan manejar caracteres no ASCII.
Documentos y procesadores de texto: documentos de texto en formatos como Markdown, JSON, YAML y XML prefieren UTF-8 por su simplicidad y capacidad de representar caracteres especiales.
Aplicaciones móviles: la mayoría de aplicaciones móviles diseñadas para Android e iOS utilizan UTF-8 para manejar texto de manera eficiente y garantizar compatibilidad entre diferentes idiomas.
Transmisión de datos: el uso de protocolos como HTTP y FTP en la gestión de redes suelen manejar texto en codificación UTF-8 para facilitar la transmisión de datos multilingües.
Conclusión
En nuestro recorrido por el estándar de codificación Unicode y sus diferentes formas de implementación, queda claro que UTF-8 es el pilar fundamental que hace posible experimentar el internet tal como lo conocemos hoy en día.
UTF-8 es crucial porque se ha consolidado como un sistema de codificación universal, eficiente y, sobre todo, compatible con los sistemas modernos. Su versatilidad permite representar y mostrar caracteres de texto de cualquier idioma, incluidos símbolos y emojis, sin problemas de compatibilidad. Además, al ser retrocompatible con sistemas antiguos como ASCII, facilita la integración con tecnologías que, aunque podrían considerarse obsoletas, siguen siendo ampliamente utilizadas.
Otra de sus grandes ventajas es que, comparado con sus contrapartes UTF-16 y UTF-32, UTF-8 es más ligero y optimiza el uso del almacenamiento al requerir menos espacio para caracteres comunes.
En definitiva, UTF-8 es el estándar de codificación Unicode más versátil y práctico para manejar texto en aplicaciones web, bases de datos, APIs y cualquier sistema que opere en un entorno globalizado y multilingüe. Por esta razón, se ha convertido en la codificación predeterminada en la mayoría de las tecnologías actuales.
También te puede interesar:
- Métodos para agregar emojis en WordPress
- Cómo desactivar Emojis en WordPress
- Cómo instalar el píxel de Facebook en WordPress
- Mejores plugins de Facebook para WordPress
- Cómo integrar WhatsApp en WordPress
¿Te ha resultado útil este artículo?

Equipo de soporte WordPress y Woocommerce en Webempresa.








